Lectura recomendada:
Plegado de consultas | Microsoft Docs
Todos hemos oído hablar del plegado de consultas (query folding en inglés) y no muchos conocemos exactamente de qué se trata.
Por definición, el plegado de consulta es la capacidad que tiene power query para traducir la consulta al lenguaje del origen, de manera que sea éste quien resuelva íntegramente la petición.
El plegado de consultas es un tema muy importante en el modelado de datos por varios motivos:
1º Las actualizaciones de datos en modelos de importación serán más eficaces en términos de uso de recursos y de duración de la actualización cuanto más se respete el plegado de consultas.
2º Cuando queremos trabajar con modelos de almacenamiento dual o DirectQuery sólo se permitirán consultas de power query que se puedan plegar totalmente.
3º La actualización incremental de datos será eficaz sólo si se mantiene el plegado de consulta, ya que, si la partición se realiza sobre un conjunto de datos que no admita el plegado, el motor de mashup tendrá que recuperar todas las filas del origen y luego aplicar los filtros para determinar los cambios incrementales.
Teniendo en cuenta lo importante que es el plegado de consultas, el nuevo elemento visual en los dataflows que nos permite saber en cada paso si se ha roto o no el plegado es tremendamente útil para primero, poder aprender qué pasos de nuestras consultas suponen una ruptura del query folding y segundo, cuando es imposible no romper el plegado de consulta, podemos mover los pasos para hacerlos en un orden que permita que el plegado se rompa lo más tarde posible.
Orígenes que admiten el plegado de consultas
La mayoría de los orígenes de datos que tienen el concepto de lenguaje de consulta admiten el plegado de consultas. Estos orígenes de datos pueden incluir bases de datos relacionales, fuentes de OData (incluidas las listas de SharePoint), Exchange y Active Directory. Sin embargo, los orígenes de datos como los archivos planos, blobs y web normalmente no lo hacen.
Transformaciones que pueden lograr el plegado
Siguiendo al pie de la letra el artículo sobre plegado de consultas de la documentación oficial de Microsoft, las transformaciones de orígenes de datos relacionales que se pueden plegar son aquellas que se pueden escribir como una única instrucción SELECT. Una instrucción SELECT se puede construir con las cláusulas WHERE, GROUP BY y JOIN apropiadas. También puede contener expresiones de columna (cálculos) que usan funciones integradas comunes admitidas por las bases de datos SQL.
Por lo general, en la lista siguiente se describen las transformaciones que se pueden doblar.
- Quitar columnas.
- Cambiar el nombre de las columnas (seleccione los alias de columna).
- Filtrar filas, con valores estáticos o parámetros de Power Query (predicados de la cláusula WHERE).
- Agrupar y resumir (cláusula GROUP BY).
- Expandir las columnas de registro (columnas de clave externa de origen) para obtener una combinación de dos tablas de origen (cláusula JOIN).
- Combinación no aproximada de consultas que pueden doblarse en función del mismo origen (cláusula JOIN).
- Anexar consultas que pueden doblarse en función del mismo origen (operador UNION ALL).
- Agregar columnas personalizadas con lógica simple (expresiones de columna de la instrucción SELECT). La lógica simple implica operaciones poco complicadas, posiblemente incluyendo el uso de funciones M que tienen funciones equivalentes en el origen de datos SQL, como matemáticos o funciones de manipulación de texto. Por ejemplo, las expresiones siguientes devuelven el componente del año del valor de la columna OrderDate (Fecha del pedido) (para devolver un valor numérico).
Date.Year([OrderDate])
- Dinamizar y anular dinamización (operadores PIVOT y UnPivot).
Vamos a ver ejemplos de todas ellas a través de un dataflow para constatar que efectivamente se mantiene el plegado de consultas:
Voy a trabajar con la tabla de Productos de Contoso y vamos a ir realizando transformaciones que nos indicarán si se rompe o no el plegado:
let
Origen = Sql.Database(«DESKTOP-4B9T98R\FRANSQL», «Contoso», [CreateNavigationProperties = false]),
Navigation = Origen{[Schema = «dbo», Item = «DimProduct»]}[Data]
in
Navigation
Nos traemos la tabla DimProduct directamente mediante la navegación y evidentemente en este paso el plegado es obvio que se mantiene
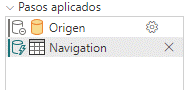
Quitar Columnas debe mantener el plegado
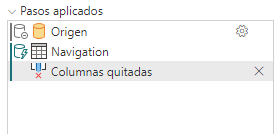
El indicador del plegado se mantiene en verde
Cambiar el nombre de columnas, idem.
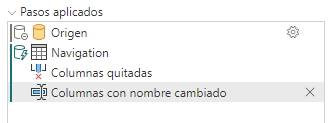
Filtrar filas, idem.
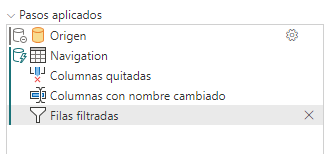
Agrupar y resumir, idem
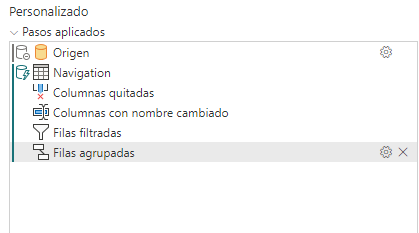
Expandir las columnas de registro (columnas de clave externa de origen) para obtener una combinación de dos tablas de origen (cláusula JOIN). Vamos a combinarla con la tabla subcategoria para traernos el nombre de la subcategoria (También funcionaría en el caso de que hubiéramos tenido en el origen marcada la opción incluir columnas de relación y expandiéramos esas columnas):

En este caso lo hacemos a través de la combinación de columnas con esas tablas.
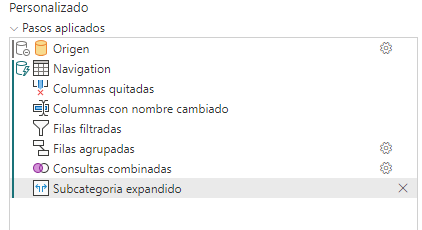
Y vamos a hacer un segundo join con categoría.
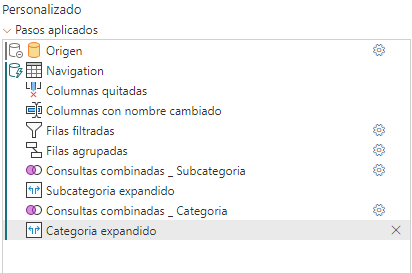
Si el origen de la tabla combinada es diferente se rompe el plegado. Voy a crear la tabla Categoria a partir de Especificar Datos y la voy a combinar
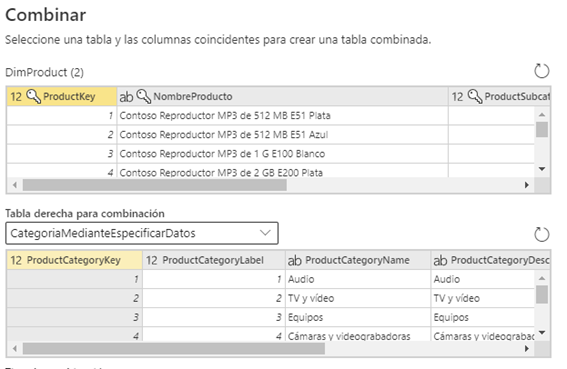
Cambiamos la tabla que combinamos.
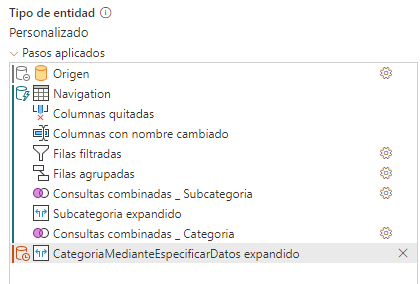
Y como vemos al expandir la tabla Categoría mediante especificar datos, como es un origen distinto al de la tabla DimProducto se rompe el plegado. A partir de aquí, cualquier transformación se hará en el mashup. Vamos por ejemplo a poner en mayúsculas el nombre de la Subcategoría.
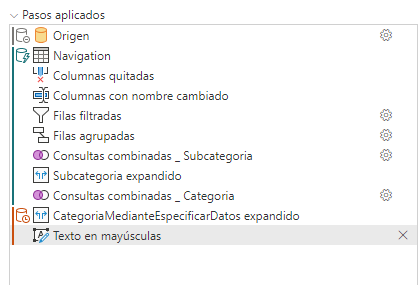
El plegado ya se ha roto por lo que esa transformación nos la muestra en rojo.
Sin embargo, ¿qué pasa si ese paso lo subimos hacia arriba antes de la ruptura del plegado?
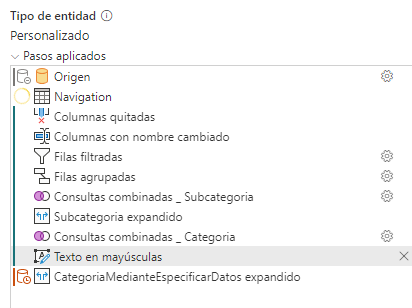
Pues que lo muestra en verde.
Esto es muy importante porque nos va a permitir, si es posible, situar el máximo número de pasos que admitan el plegado antes de su ruptura.
Volvamos a cambiar la tabla de categoría por la propia del origen y sigamos haciendo pasos que mantengan el plegado
Ya hemos visto que transformaciones simples como cambiar texto a mayúscula, que se pueden hacer en el lenguaje nativo, no rompen tampoco el plegado
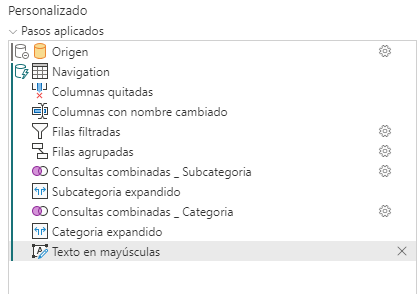
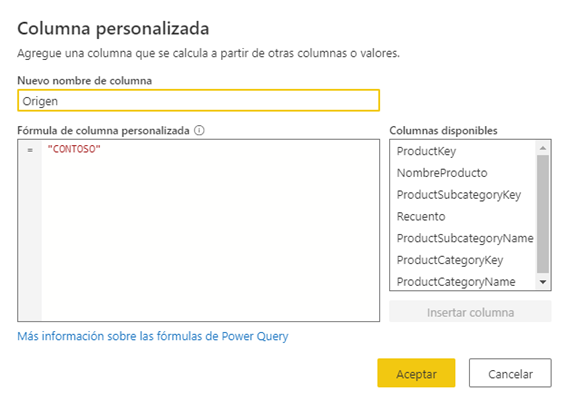
Y la creación de columnas personalizadas simples tampoco rompen el plegado
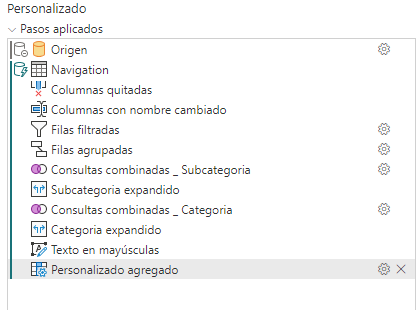
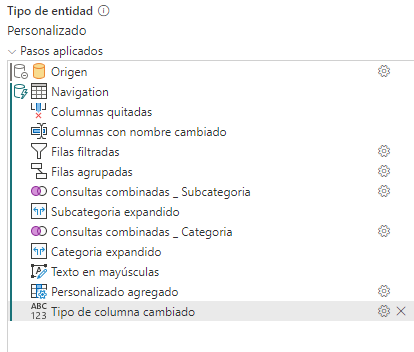
Cambiar el tipo de datos en principio tampoco romperá el plegado, en este caso transformamos la columna presonalizada agregada desde any a text.
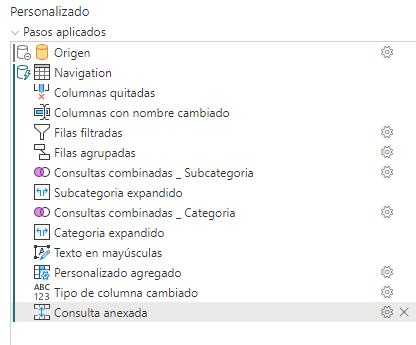
Y anexar consultas (siempre que sean del mismo origen) tampoco romperá el plegado.
Por último, la anulación de dinamización de columnas o la dinamización (PIVOT o UNPIVOT) tampoco supone una ruptura del plegado
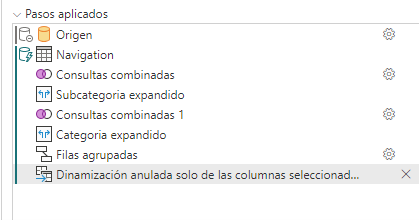
¿Qué transformaciones impiden el plegado?
Como hemos visto en el ejemplo, combinar consultas, o anexarlas, cuando el origen de datos es diferente.
Agregar columnas personalizadas con lógica compleja. La lógica compleja implica el uso de las funciones M que no tienen funciones equivalentes en el origen de datos
Agregar columnas de índice.
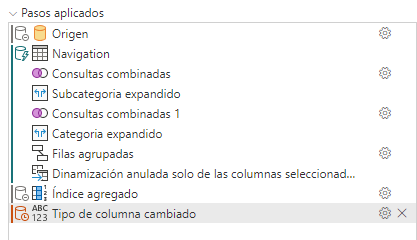
En el manual de Microsoft define como uno de los pasos que rompe el plegado el cambiar el tipo de datos, sin embargo yo he probado a cambiar el tipo de datos de numérico a texto, por ejemplo y mantiene el plegado en esos casos:
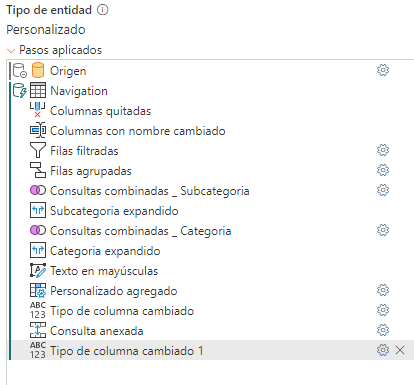
En todo caso, rompe el plegado siempre la utilización de funciones como Table.Buffer() que precisamente sirve para almacenar en caché los datos y a partir de ahí realizar las transformaciones sin llamar al origen por lo que es obvio que esa función rompe el plegado.
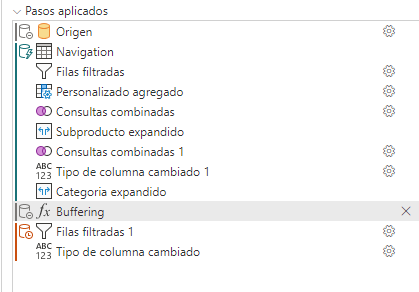

Por último, cabe analizar el uso de consultas nativas.
La utilización de consultas nativas va a suponer que cualquier paso posterior se realice siempre en memoria rompiendo el plegado. ¿Es por ello inviable el uso de consultas nativas? Pues evidentemente si en la consulta nativa pasas todos los elementos que puedes mandar al origen sin romper el plegado pues da igual que utilices una consulta nativa o que lo hagas directamente en M, al final, en este caso, pues como siempre digo el usuario debe utilizar el lenguaje en el que se sienta más cómodo y es posible que se sienta más cómodo en un entorno sql que en un entorno de M. En todo caso hay que ser consciente de esto, de que cualquier paso posterior a una consulta nativa, va a estar marcado como fuera del plegado y por tanto se ejecutará en memoria y no en el origen.
Por ejemplo vamos a coger y vamos a crear una consulta nativa a partir de la propia query que nos genera la tabla que hemos ido creando en el ejemplo. Para ello nos iremos al último paso, botón derecho y pulsaremos en “Ver consulta de origen de datos”.
Copiamos la consulta y la creamos como consulta nativa en otra query:
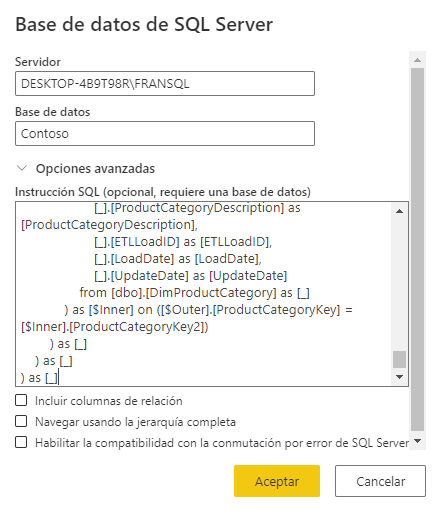

Nos aparece este warning, damos a continuar y obtenemos la misma tabla que con todos los pasos que hicimos en M

Pero en este caso, cualquier simple paso posterior como cambiar el tipo de datos nos lo va a mostrar en rojo ya que tras una consulta nativa nunca existirá plegado de consultas.
Os invito a que juguéis con vuestros datos en los flujos de datos averiguando qué transformaciones mantienen o eliminan el plegado de consultas y optimizando al máximo de este modo vuestro proceso de importación de datos.
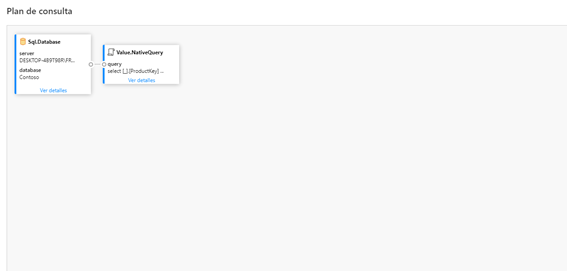
Otra de las novedades que ha presentado el Power Query online es la integración de el plan de consulta en su versión preliminar
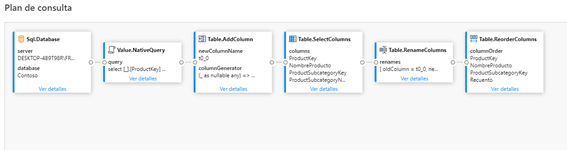
Ahí podemos observar la gran diferencia entre el plan de consultas de una query que mantiene el plegado y que no lo mantiene, aun siendo el mismo resultado final:
- Plan de consultas con plegado:
- Plan de consultas con ruptura del plegado:
6 comentarios