Tras la euforia inicial de ver como podía cargar una tabla de un dataflow gen2 directamente a una tabla de SQL Azure y todo lo que ello podía suponer, tocaba…
Consumir flujos de datos en Power Query para Excel

Los usuarios de la hoja de cálculo verde están de enhorabuena ya que se encuentra operativo el conector de Flujos de Datos para Power Query en Excel de manera que…
Traer como origen una tabla de un conjunto de datos de Power BI y limpiar nombres de columnas.

Una pregunta tremendamente habitual: ¿Cómo puedo acceder los datos de mi modelo? ¿Sabíais que podemos conectarnos desde un flujo de datos a un conjunto de datos? Esto no está muy…
Mes de febrero cargado de eventos sobre Dataflows
Este mes de febrero de 2021 ha estado tremendamente cargado de eventos en la Comunidad de Power BI. Por mi parte, he tenido la suerte de participar en las III…
Mantener el plegado de consulta con consultas nativas
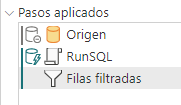
Durante este fin de semana e impartido dos charlas en Power Platform Bootcamp de Madrid y Barcelona en la que el tema principal era el tratamiento del plegado de consulta…
Aprendiendo qué es el plegado de consulta con la nueva funcionalidad de visualización del plegado en dataflows.
Lectura recomendada: Plegado de consultas | Microsoft Docs Todos hemos oído hablar del plegado de consultas (query folding en inglés) y no muchos conocemos exactamente de qué se trata. Por…
Automatización de las actualizaciones de dataflows y datasets

A principios de octubre, el genio de los dataflows Matthew Roche publicaba en su blog que ya estaba disponible la posibilidad de automatizar el refresco de los datasets dependientes de…
Consolidación de tablas de calendario en Dataflows

Como todos sabéis todos mis proyectos de Power BI los desarrolo a partir de ETL en Dataflows. Hasta ahora siempre utilizaba mis tablas de calendario, tiempo y período en DAX,…
Dataflows admite cuadro de dialogo en la consulta nativa de SQL pero provocando de momento un error crítico si usas parámetros
Lo que esta mañana parecía una grandísima noticia, la llegada de los cuadros de diálogo en las consultas nativas de SQL en dataflows se ha convertido en una auténtica pesadilla…
Evitar las entidades calculadas cuando utilizas un flujo de datos como origen de otro flujo de datos.
Mediante este menú podemos agregar entidades vinculadas. Reza en su menú: “La vinculación a entidades de otros flujos de datos reduce la duplicación y ayuda a mantener la coherencia en…