Superada la semana de resaca de su lanzamiento y aún con muchas incógnitas y descubrimientos casi a diario, voy a comenzar a crear algún documento sobre el uso de los…
Introducción a los cálculos visuales
Superada la semana de resaca de su lanzamiento y aún con muchas incógnitas y descubrimientos casi a diario, voy a comenzar a crear algún documento sobre el uso de los…

Serie funciones window DAX Introducción En diciembre de 2022 se introdujeron en el lenguaje DAX las funciones de ventana (Window Functions) que son unas nuevas funciones de tabla que…
Tras la euforia inicial de ver como podía cargar una tabla de un dataflow gen2 directamente a una tabla de SQL Azure y todo lo que ello podía suponer, tocaba…
En diversas ocasiones he hablado del plegado de consulta y su importancia en Power Query, dedicando un buen número de páginas a ello en mi libro “Power BI Dataflows”, sobre…

La creación y utilización de funciones personalizadas en Power Query es un gran desconocido para el usuario habitual de la herramienta pero que nos va a permitir saltar límites insospechados…
Ayer preguntaban en el grupo Power BI Español esta cuestión que me resultó curiosa y procedí a investigar cómo hacer el flujo en Power Automate: Hola, una pregunta. Alguien sabe…
Esta mañana hemos desayunado con la noticia de la aparición de nuevas funciones de información en DAX. Y vamos a desgranar superficialmente qué podemos y qué no podemos hacer con…
II Entrega Vamos a seguir avanzando en el estudio de las particularidades de las funciones Window sobre las que realizamos un primer acercamiento en nuestro post anterior:Primer acercamiento a las…
El 15 de julio de 2020 aparecieron los grupos de cálculo por primera vez en Power BI Desktop mediante la posibilidad de implementarlos a través de Tabular Editor. Por aquel…
1.- Guardar el archivo pbix como pbip. 2.- Abrir nuestra plantilla para documentar 3.- Introducimos la ruta donde está nuestro archivo model.bim del pbip El model.bim se encuentra siempre en…
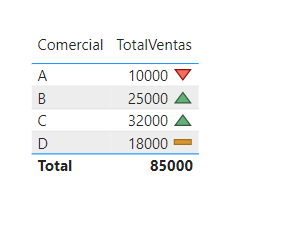
Hace unos años, tuve el enorme privilegio de descubrir que los iconos del formato condicional podían llamarse mediante su nombre y extraje del propio Power BI un listado de los…