Tras la euforia inicial de ver como podía cargar una tabla de un dataflow gen2 directamente a una tabla de SQL Azure y todo lo que ello podía suponer, tocaba un análisis un poco más exhaustivo de la herramienta de la que se pueden extraer unas primeras conclusiones.
Me queda muchísimo que estudiar sobre ello y este primer acercamiento es meramente empírico, sin consultar documentación alguna, por lo que desde ya pido disculpas si me equivoco en alguna de mis primeras impresiones.
Lo primero que observamos es algo que llevo echando muchísimo en falta desde el principio en los flujos de datos primarios o originales o versión 1, como queráis llamarlos:
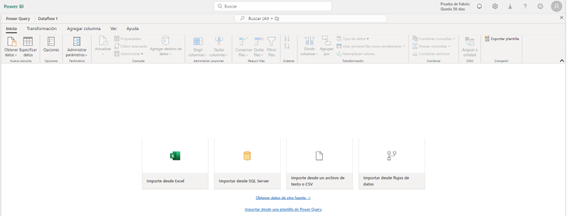
Entramos directamente a Power Query no a los conectores de datos que no avanzan hacia Power Query hasta que no los usas.
Eso ya de primeras nos va a permitir antes que nada revisar las Opciones del proyecto, la privacidad, la puerta de enlace, el culture que vamos a usar, etc.
Importante también que nos va a permitir importar desde una plantilla de Power Query

Esto nos va a permitir realizar una migración sencilla de DF1 a DF Gen2 como voy a hacer en esta demo.
Importo mi plantilla y ya tengo mi modelo migrado, simplemente requiere revisar las conexiones y credenciales.
A nivel de interfaz pocas cosas más cambian. Están absolutamente todas las funcionalidades de Power Query Online
Pero lo que más llama la atención sin duda y lo que ha cambiado realmente las reglas del juego es la opción de poder agregar un destino de los datos.
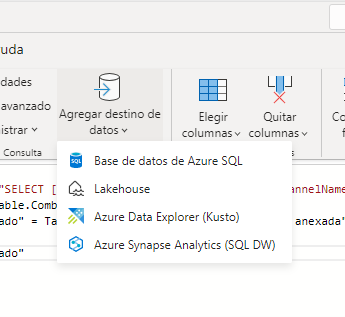
Esto significa que los datos transformados en nuestro flujo de datos no se van a almacenar en el propio servicio de power bi en formato .csv como hasta ahora sucedía sino que vamos a poder elegir el destino entre los 4 que muestro en la imagen:
Base de datos de Azure SQL
Lakehouse
Azure Data Explorer
Azure Synapse Analytics
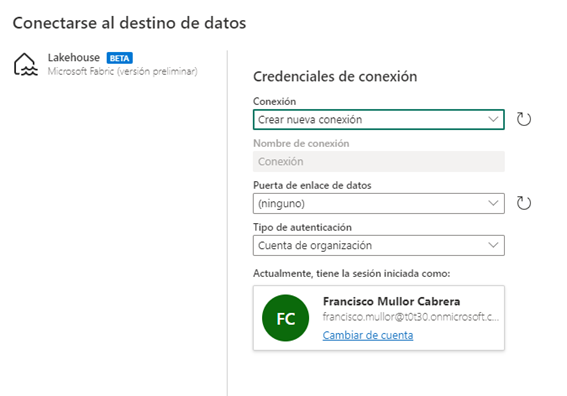
Vamos a elegir Lakehouse en este caso
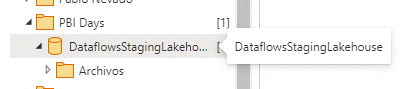
Elegimos el destino que como vemos es un LakeHouse en la propia área de trabajo donde hemos creado el flujo que es precisamente lo que apovisionaba en la primera imagen que puse de “haciendo cosas”
Y ojo aquí llega otra grandísima novedad, el método de actualización:
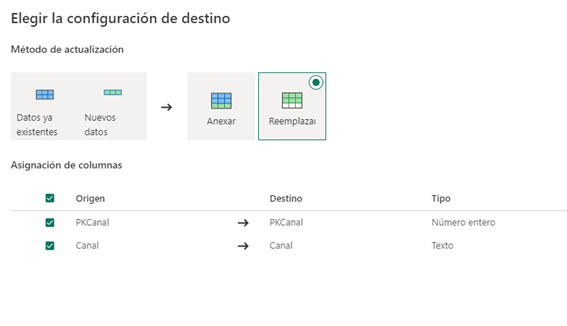
Vamos a poder anexar los datos o reemplazarlos.
La anexión que es la gran novedad nos va a permitir abrir escenarios que hasta ahora no se podían abordar en Power BI fácilmente.
1º Creación de snapshots de datos
2º Posibilidad de consolidación de ficheros sin tener que mantener los ficheros originales siempre. Imaginad por ejemplo el escenario de los Excel diarios que va rellenando un equipo de ventas. No vamos a necesitar guardarlos todos, simplemente actualizar cada nuevo Excel en el flujo de datos guardándolos en forma de anexión en el origen que decidamos
Me ha llamado poderosamente la atención de manera negativa que no se puedan asignar destinos en bloque, a todas las consultas a la vez, hay que ir una a una, aunque seguiré investigando por si me he saltado esa posibilidad.
También me ha llamado la atención que se puede asignar un destino a tablas que no hemos habilitado la carga, igualmente me toca investigar por qué. En este primer flujo las dejaré sin asignación a ver qué sucede.
Damos a “publicar” y lo primero que vemos es que se cierra rápidamente. Toda la fase de comprobaciones tan tediosas a veces en DF1, se realizan aquí en segundo plano, un gran paso en este sentido.
El Flujo se guarda como Dataflow 1 sin permitirnos en ningún momento en esta primera fase de creación modificar el nombre a nuestro antojo. Esto creo que es debido a una de las novedades también en esta versión, desde el minuto 1 que empiezas a crear el flujo, este ya se va autoguardando y por eso escoge un nombre dummy que luego podremos cambiar.
Al volver a nuestro área de trabajo vemos los cambios que ha realizado la creación del flujo:
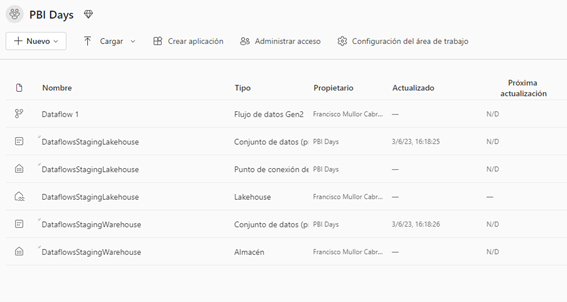
Bajo el nombre de DataflowsStagingWarehouse nos ha creado dos conjuntos de datos predeterminados, un Almacén de datos y un Punto de conexión SQL y un Lakehouse.
Los almacenes están vacíos dado que en este punto hemos publicado el Flujo pero aun no hemos realizado la primera actualización. Vayamos a ello.
Primero voy a reentrar a mi flujo con el objetivo de renombrarlo
Publicamos de nuevo y listo

Ahora sí, vamos a actualizarlo…
Otro de los cambios significativos que se puede observar es la información que arroja sobre el historial de actualización
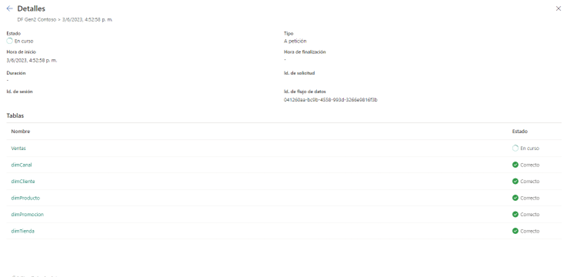
Ahora va mostrando en un cuadro de diálogo todo el proceso sin necesidad de descargar el dichoso csv, aunque también tienes la opción de descargarlo si lo deseas.
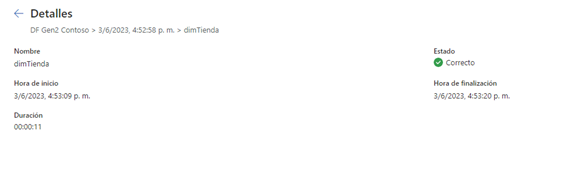
Curiosamente el tiempo de actualización de un mismo modelo en DF 1 y DF Gen 2 no es mejor en DF Gen2. No es aquí donde vamos a obtener la ganancia sino en todo lo que supone poder tener los datos directamente en el LakeHouse o en SQL. He creado un modelo exactamente igual a partir de datos de Contoso que tengo alojado es un SQL Azure
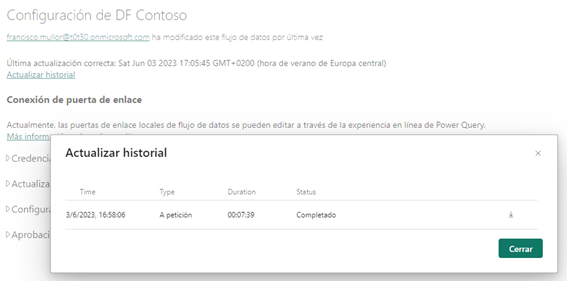
El DF1 tardó 7:39 en su primera actualización.
Mientras que el DF Gen2 tardó algo más de 12 minutos en cada una de sus actualizaciones.

Por otra parte, cada actualización del DF Gen2, además de actualizar las tablas principales, crea una versión de los datos actualizados.
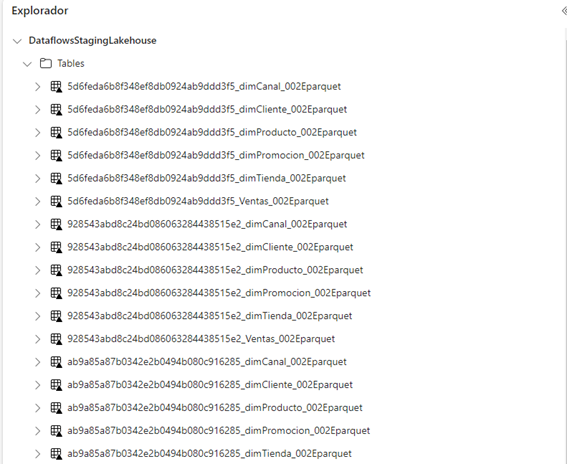
Esto habrá que ver cómo se gestiona en el lago de datos y como establecer un sistema de borrado ya que al fin y al cabo son objetos que ocupan espacio que hay que pagar por él. Es lo mismo que sucedía cuando los flujos tradicionales los alojábamos en ADLS2
A partir de aquí, trabajar con el Lago de Datos es lo que mayor valor confiere si cabe a los flujos de datos Gen2.
Crear tu modelo directamente en el servicio
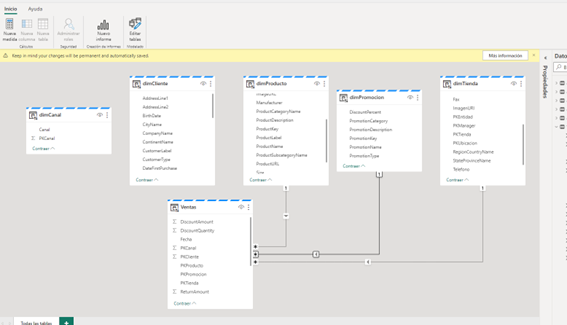
Con medidas, roles, etc…
Y crear informes sobre ese modelo
Sin salir ni un momento del mismo es el principio de un cambio de reglas del juego total y que seguro, sabiendo como trabaja Microsoft y como ha mejorado en los últimos 8 años un producto como Power BNI, confieren a Fabric un lugar muy importante en el análisis y la ciencia de datos combinado con las nuevas capacidades de inteligencia artificial.
En resumen:
- Interfaz prácticamente igual a la de DF1, con la salvedad de la entrada directa a Power Query Online
- Posibilidad de importar archivos de plantilla de Power Query, para facilitar la migración desde DF1.
- Cambio total de las reglas del juego con la opción de almacenar los datos en diferentes sistemas como SQL Azure, LakeHouse, Synapse o Kusto
- Posibilidad de almacenar datos tipo snapshots al poder anexar en lugar de actualizar las consultas
- Validación en segundo plano y guardado automático, aunque con tiempos de actualización por el contrario más altos que en DF1
- Creación en el lago de datos de una copia de cada actualización (pendiente de estudiar como se gestiona esto)
- Y opciones de creación de modelos e informes directamente en el servicio de Power BI a través del lago de datos.
ADDENDA:
Si haces el flujo y no asignas ningún destino de datos, el flujo falla, pero ojo que el error no lo explica

Este pequeño bug solo ocurre (y dio la casualidad de que lo reproduje) cuando el flujo de datos se crea a partir de una plantilla de otro flujo de datos gen2 que tuviera definidas los destinos.
Esa definición se queda en la plantilla grabada y no basta con eliminar la definición de salida del propio flujo (tablas ocultas que crea internamente) y es por ello que se produce el error. En cualquier otro caso no he apreciado errores en la carga si no están definidos los destinos y en ese caso el flujo se graba como si se tratase de un flujo de datos normal en el servicio y generando los correspondientes deltas en el lakehouse.
Si os encontrais este bugo, si haces el flujo y asignas una sola tabla y el destino es Lakehouse, el flujo se ejecuta, guarda todas las tablas habilitadas para la carga como tablas de la actualización (ya dijimos que en cada actualización guarda una copia de todas las tablas) y guarda solo las tablas asignadas al destino con su nombre correspondiente:
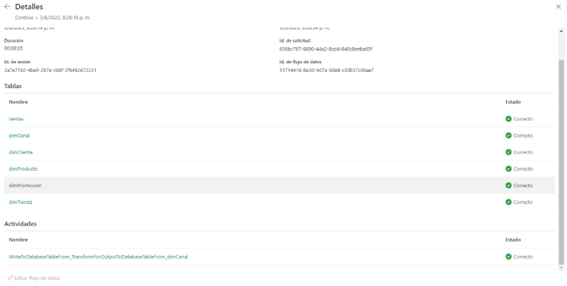
Si haces el flujo y asignas una sola tabla y el destino es SQL Azure, el flujo se ejecuta, la tabla se crea y se actualiza en el SQL y todas las tablas se guardan también en el Lakehouse como en todas las actualizaciones que se realizan. La conclusión es que en el Lakehouse, siempre que halla al menos una asignación, se va a guardar la copia completa de la actualización (comportamiento normal de un delta), como ocurría en ADLS2 y las tablas con su nombre van al destino que tengan asignado si lo hubiera.
También pueden combinarse los destinos, unas tablas ir a un sitio y otras a otro.
2 comentarios