
Serie funciones window DAX
Introducción
En diciembre de 2022 se introdujeron en el lenguaje DAX las funciones de ventana (Window Functions) que son unas nuevas funciones de tabla que tienen por objetivo navegar sobre una tabla ordenada y particionada para obtener filas absolutas y relativas.
Se denominan colectivamente funciones de ventana porque están estrechamente relacionadas con las funciones de ventana SQL, una característica poderosa del lenguaje SQL que permite a los usuarios realizar cálculos en un conjunto de filas que están relacionadas con la fila actual.
Son muchos los casos de uso que nos podemos encontrar para estas funciones:
- Creación de “running totals”
- Pareto
- Clasificación ABC
- Comparación ventas mes actual con el anterior
- Cálculo de promedios móviles
Lo primero que se nos viene a la cabeza cuando vemos ese listado es: “todo esto yo ya lo puedo hacer con las funciones DAX actuales”.
Rotundamente: ¡SI!
Como dicen Ferrari y Russo en sqlbi.com las funciones de ventana por sí mismas no aumentan la expresividad de DAX. La mayoría (si no todos) de los cálculos realizados con ellas se pueden expresar con código DAX más complejo, por lo que el objetivo principal de las funciones de ventana es la simplificación de los cálculos y mejorar su rendimiento. Pero ojo, simplificación de los cálculos no significa que sean funciones sencillas de entender y en palabras de Jeffrey Wang “las funciones de ventana de DAX son poderosas, pero más complejas que la mayoría de las otras funciones de DAX, por lo tanto, requieren más esfuerzo para aprender”.
Las funciones de ventana que se han introducido son tres: WINDOW, OFFSET e INDEX (aunque realmente diría que con WINDOW se podría abarcar todas las casuísticas como veremos más adelante). OFFSET e INDEX son lo que conocemos como sugar syntax de WINDOW, expresiones azucaradas de las que tenemos infinidad de ejemplos a lo largo de la existencia de DAX como TOTALYTD, la expresión azucarada de CALCULATE([medida], DATESYTD([fechas])).
Y además se han introducido otras funciones que sirven de argumento a estas como son ORDERBY, PARTITIONBY y recientísimamente MATCHBY que explicaremos también en esta serie.
Sintaxis
- Funcion(
<selección de fila>(obl),
<tabla>(opc),<orden>(opc),<blancos>(opc),<partición>(opc)<coincidencias>(opc))
- Las tres funciones WINDOW, INDEX y OFFSET tienen la misma estructura. Se diferencian básicamente por el parámetro obligatorio que es única y exclusivamente la selección de fila y que dependiendo de una u otra función selecciona unas filas u otras. De hecho, los mismos resultados de las funciones INDEX y OFFSET podrían obtenerse con la función WINDOW(sugar syntax como he comentado).
- En las funciones INDEX y OFFSET el parámetro obligatorio (
) consta de un único argumento, mientras que en WINDOW puede constar de 2 a 4. - INDEX nos devuelve la Nesima fila en una posición fija (Absoluta) de la partición actual
- OFFSET nos devuelve la Nesima fila a una cierta distancia (posición relativa) de la fila actual
- WINDOW devuelve todas las filas entre un límite inferior y un límite superior pudiendo elegir entre posiciones absolutas o relativas.
WINDOW(X,ABS,X,ABS)=INDEX(X)
WINDOW(X,REL,X,REL)=OFFSET(X)
Resultados de las funciones de ventana
Para ver qué resultados podemos obtener y como funcionan las funciones WINDOW nada mejor que con esta imagen del blog de Jeffrey Wang http://pbidax.wordpress.com donde el autor ha profundizado mucho sobre estas funciones:
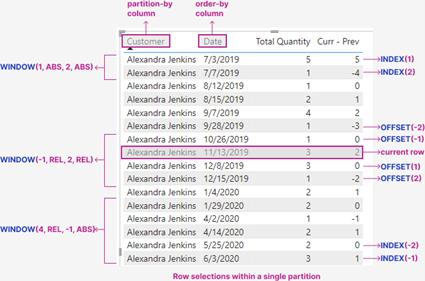
En la imagen podemos observar una tabla en la que tenemos los datos totales de cantidades vendidas a una cliente y ordenadas por fecha.
Particionar por cliente, significa que a la hora de realizar el cálculo va a dividir las tablas en subtablas ordenadas por cada cliente, por lo que para los cálculos de un cliente no tendrá nunca en cuenta las filas de otros clientes.
En cuanto a la ordenación, va a permitir que podamos discernir la posición de cada línea dentro de la tabla ordenada para, según el requerimiento, utilizarla o no en el cálculo. Veamoslo con ejemplos:
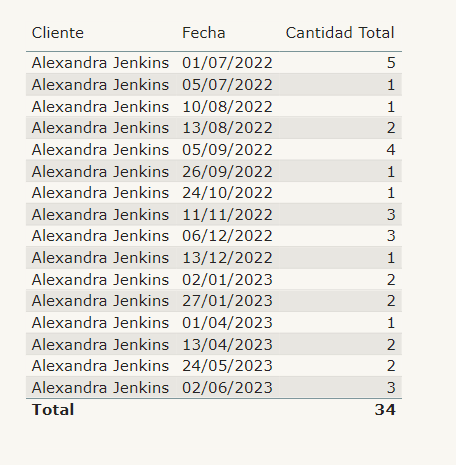
Partimos de esta tabla de Adventure Works, igual a la de Jeffrey excepto por que las fechas son más recientes.
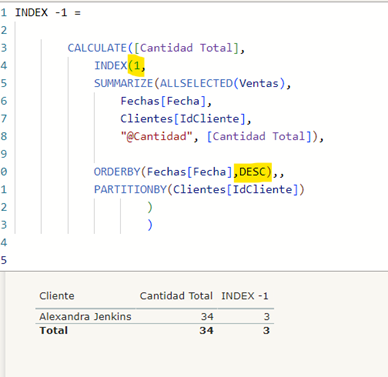
Si hacemos el INDEX (1) el resultado debe ser para todas las filas 5
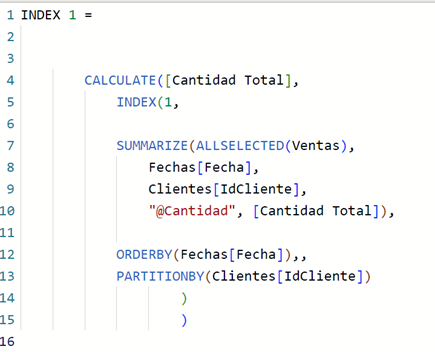
Estamos calculando la cantidad total filtrando por el index 1, es decir la cantidad total que se obtiene en la primera fila de la tabla que incluimos en la relación. Primera fila que establecemos como la primera fecha en la que tenemos cantidad y además para cada cliente, es decir en una tabla donde pongamos solo los clientes, nos devolverá su primera cantidad comprada dentro del contexto de evaluación que estemos analizando.

Para Alexandra Jenkins el INDEX 1 es 5 que corresponde a la primera fila de la imagen.
Sobre la tabla que incluimos en el parámetro “relación” como podemos observar estamos reproduciendo fielmente la visual de tabla de la que partíamos de ejemplo creando una tabla sumarizada de las cantidades totales por fecha y por cliente. Y utilizamos el modificador de contexto ALLSELECTED, porque si no lo usáramos, para cada línea nos devolvería el mismo valor que [Cantidad Total] ya que el contexto de filtro de la fila de la visual se aplicaría a la medida, tenemos que eliminar ese contexto de la fila mediante ese modificador ALLSELECTED.
En esta imagen podemos verlo:
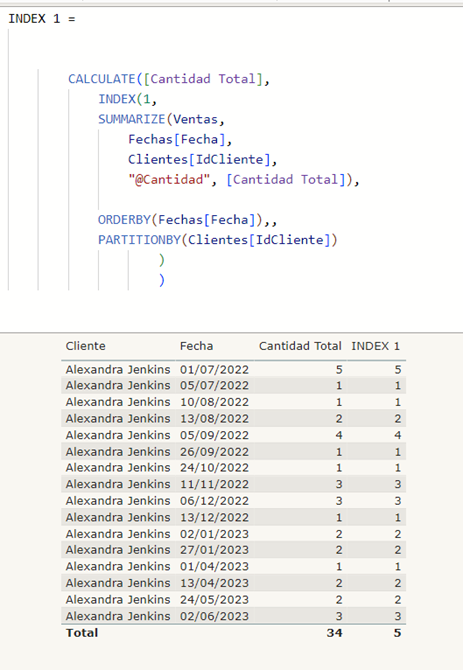
Sin el ALLSELECTED, solo en la fila del total donde no existe contexto de fila, nos da el resultado esperado. En las demás filas para cada fila su cantidad es la primera de la tabla.
No podemos utilizar en el parámetro de relación la tabla Ventas tal cual
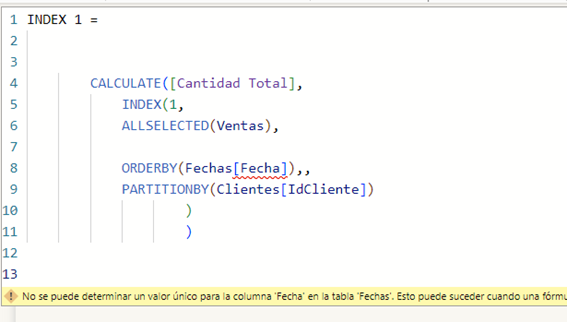
Lo primero porque no podríamos ordenar por la Fecha de la dimensión o por el cliente de la dimensión cliente, al no ser campos directamente de la tabla que figura como “relation”
Incluso si utilizaramos los campos directamente de la tabla de hechos, nos daría un error porque el parámetro “relation” requiere una tabla que no pueda contener filas duplicadas.
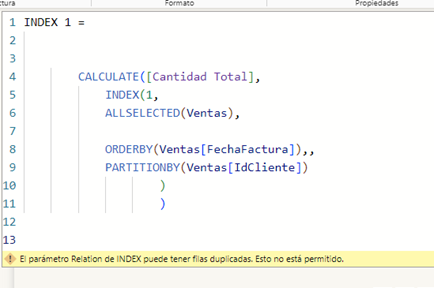
Es por ello que replicamos la tabla de la visual que sabemos que no contiene elementos duplicados ya que una tabla sumarizada siempre va a contener elementos únicos y, además, vamos a usar en la sumarización los ids dimensionales: Fecha e IdCliente de las dimensiones
El INDEX (-1) debe devolvernos 3
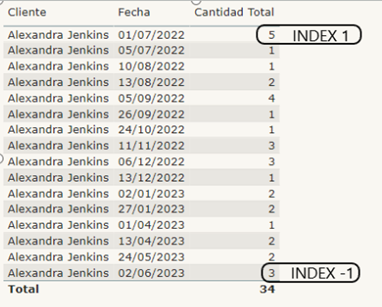
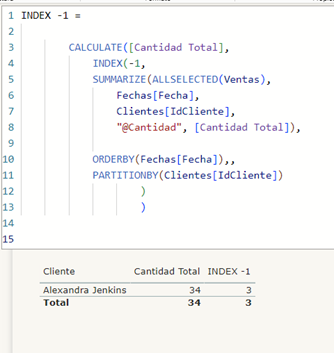
Esta función daría el mismo resultado que el INDEX1 con el order by descendente (es ascendente por defecto)
Volviendo al cuadro de Jeffrey
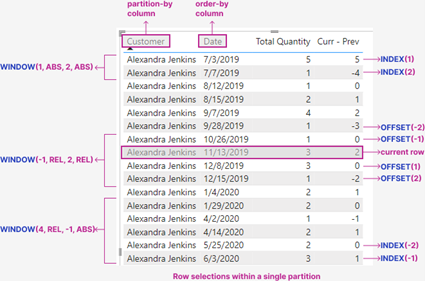
Si con INDEX obteníamos posiciones absolutas dentro del orden de la tabla, con OFFSET, de la misma forma, vamos a obtener posiciones relativas de manera que con respecto a cada fila de la tabla podremos, por ejemplo, obtener el valor anterior o posterior.
Veamos el OFFSET -1
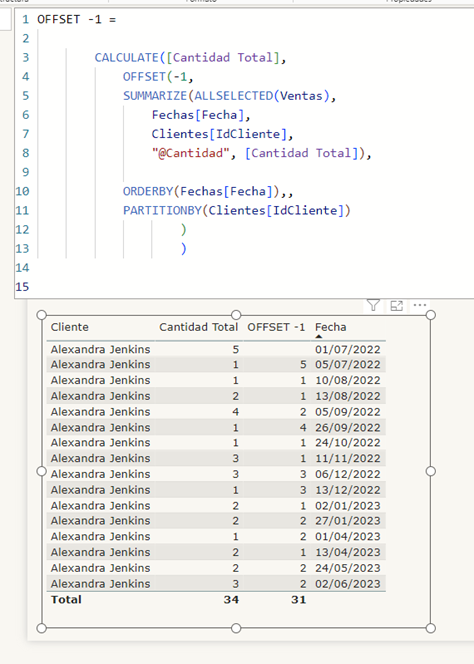
No hay mucho que comentar, para cada fila nos va a devolver la cantidad existente en la fila anterior. Abriendo un poco sus mentes podremos encontrar infinidad de escenarios donde sea interesante utilizar esta función y que a lo largo de esta serie trataremos pormenorizadamente. Nos quedamos en este punto simplemente con entender qué hace la función.
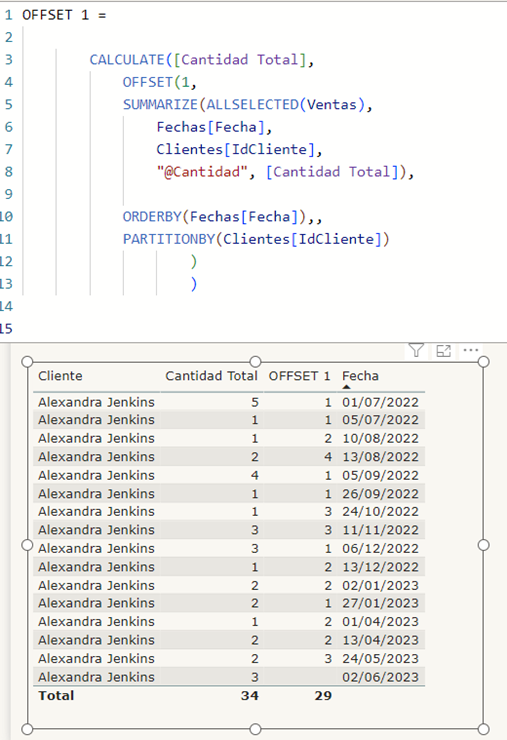
El OFFSET (1) pues igual pero con la cantidad de la fila posterior
Por último indicar que la función WINDOW haría lo mismo pero indicando nosotros el rango entero de filas que queramos que tenga en cuenta
Un WINDOW -2 REL 0 REL, por ejemplo analizará las tres filas anteriores a las del contexto, incluida ésta
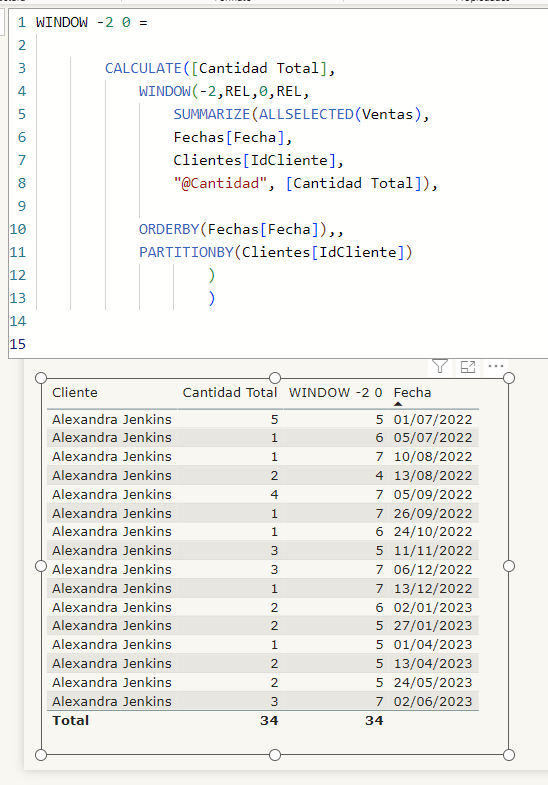
La primera fila totaliza 5 que es el total de ella misma
La segunda 6 (5+1)
La tercera 7 (5+1+1)
La cuarta 4(1+1+2)
Y así sucesivamente.
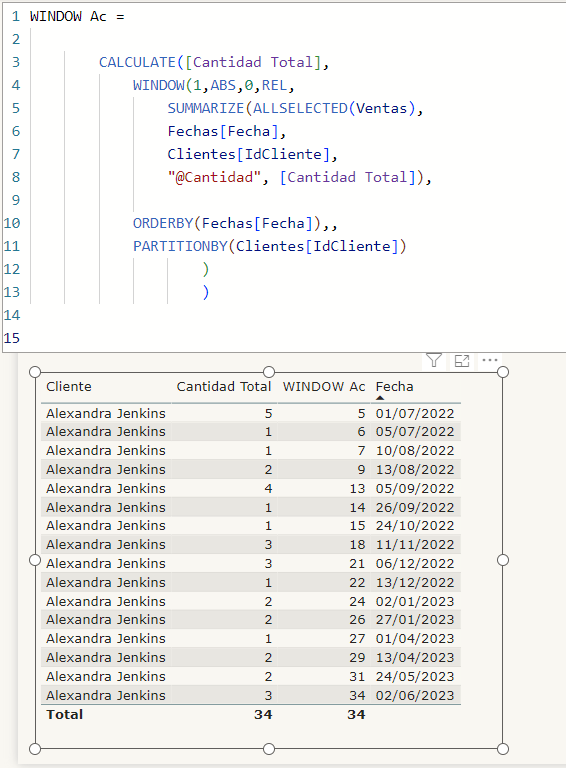
Si usamos WINDOW 1 ABS 0 REL estaremos sumando desde la primera fila hasta la fila del contexto. ¿Os suena de algo? Pues es acumular, realizar un running total de la manera más sencilla y eficiente.
En resumen, las funciones WINDOW aun siendo todavía grandes desconocidas, nos ofrecen un abanico de posibilidades a la hora de calcular impresionante.
¿Os gustaría conocerlas conmigo?
Intentaré en próximas semanas seguir la serie acercándome detenidamente a casos de uso concretos.
4 comentarios